Harness the Power of RAG with LLMs, Vector Stores, and Langchain: A Comprehensive Guide
Large Language Models (LLMs) such as GPT-4, Claude 3, etc. have revolutionized the field of natural language processing, enabling machines to generate human-like text with remarkable fluency and coherence. These powerful models, trained on vast amounts of data, have demonstrated an impressive ability to understand and generate language, opening up new possibilities in various applications such as content creation, creative writing, and conversational AI.
However, despite their impressive language generation capabilities, LLMs often lack the ability to produce factually accurate information. This limitation arises because LLMs are trained on vast datasets of text and learn patterns within the data, but they do not inherently understand or verify the facts. Again these data contain biases, inconsistencies, or outdated information. As a result, the generated text, although linguistically fluent, may not always align with real-world facts or the most up-to-date information. This phenomenon is often called a ‘hallucination’.
Retrieval-Augmented Generation (RAG) is a powerful technique that combines the language generation capabilities of LLMs with external knowledge sources, allowing the models to access and incorporate relevant factual information during the generation process.
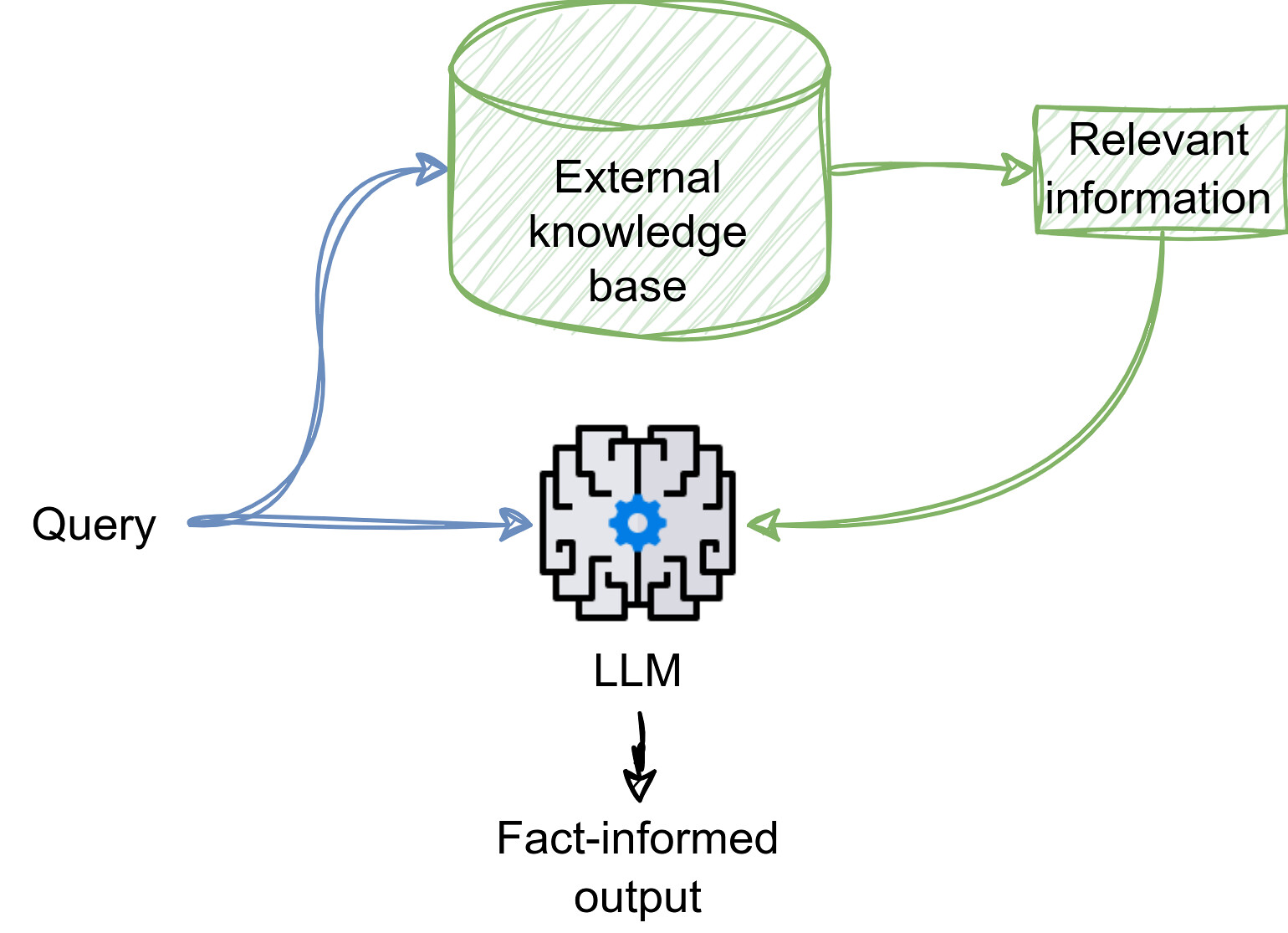
What is Retrieval-Augmented Generation (RAG)?
RAG is a powerful technique that uses an external knowledge base (KB) to provide relevant and/or up-to-date information to the LLM. The knowledge base can be domain-specific documents, websites, or even PDFs. It powers the ‘chat with PDF’, ‘chat with website’ type applications.
As depicted in Figure 1, a user’s query is used to retrieve relevant information from the KB and is passed to the LLM along with the query. Now the LLM has access to the facts or updated information to look at and generate its response. Generally, a RAG system has two key components:
- The Retriever: Think of it as a super librarian with a massive digital library (the KB). The retriever searches through mountains of text data (articles, books, etc.) to find information relevant to a specific topic. It uses clever techniques like keyword matching or even fancy text analysis to identify the best sources.
- The Generator (LLM): This is where the LLM, our powerful language model, comes in. The retriever feeds the LLM with the most relevant information it finds. Instead of having to dream up everything from scratch (hallucinating), the LLM has a solid foundation of real-world information to work with, ensuring a more accurate and informative response.
Building a RAG System with a Step-by-Step Guide
Building an RAG system using LangChain and LLMs involves several steps. To get started, you’ll need to set up your development environment. Ensure you have Python installed and then install the necessary libraries.
pip install langchain langchain-openai langchain-community unstructured faiss-cpu
To develop the system, we would first prepare the knowledge base, then develop the retriever pipeline, and finally integrate the LLM to generate the response.
1. Preparing the Knowledge Base (KB)
Preparing the knowledge base is a crucial step in building an effective RAG system. Let’s walk through the process of creating a well-organized knowledge base using Langchain. We will cover loading data, chunking data, initializing a vector database with FAISS, and preparing the retriever.
1.a. Load Data
First, we need to load the data that will form our knowledge base. This data can come from various sources such as HTML files, PDFs, or text documents. In this example, we’ll use an HTML file:
from langchain_community.document_loaders import UnstructuredHTMLLoader
SOURCE_FILE = "path/to/your/file.html"
loader = UnstructuredHTMLLoader(SOURCE_FILE)
data = loader.load()
This code loads an HTML file using the UnstructuredHTMLLoader from Langchain. Make sure to replace "path/to/your/file.html" with the actual path to your HTML file.
1.b. Chunk Data
Large documents need to be split into smaller chunks for better processing and providing the correct piece of information to the LLM. Next, we’ll split the loaded data into smaller, manageable chunks.
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=32)
chunks = splitter.split_documents(data)
Finding the right chunk size and overlap can be tricky. You can experiment with different chunk and overlap sizes to find the optimal one for your task. Smaller chunk size like 128 or 256 enables us to get fine-grained information but may produce a large number of chunks resulting in higher consumption of memory and computing resources.
1.c. Initialize the Vector Database
Vector databases like FAISS (Facebook AI Similarity Search) work by storing and efficiently searching high-dimensional vector representations of data. We will first convert each text chunk into a numerical vector (known as embeddings) using an embedding model (in our case, OpenAIEmbeddings). These vectors capture the semantic meaning of the text in a high-dimensional space. Then we will store the embeddings into a Vector DB (in our case, FAISS).
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(chunks, embeddings)
To run this code, you need to set the OpenAI API key in your environment variables. Create an API key and set it in your environment variables using the following command:
export OPENAI_API_KEY=XXXX
With this, our KB is prepared. Let’s now jump into preparing the retriever pipeline.
2. Retriever Pipeline and LLM integration
The retriever pipeline starts with a user query. The query is converted into embeddings using the same embedding model that was used to create the KB. A vector similarity metric like cosine or Euclidean distance is used to get top K similar text chunks. These chunks are then added to the prompt with the original query and passed to the LLM to generate the response.
We use a ‘chain’ from Langchain to define the pipeline.
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(model="gpt-4o", temperature=0.3)
retriever = db.as_retriever(k=10)
chain = (
{
"contexts": itemgetter("question")
| retriever
| (lambda x: [d.page_content for d in x]),
"question": itemgetter("question"),
}
| prompt
| llm
| StrOutputParser()
)
With this, the RAG pipeline is complete. We can use this pipeline using the chain.invoke() fucntion. You can find the full implementation in this GitHub repository.
Comparison
Now, let’s compare the response of the RAG system with a straightforward LLM-based QA system. To build a KB for the RAG system, we use the BERT documentation from Hugging Face. The straightforward QA system can be established with the following code snippet:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o", temperature=0.3)
prompt = "XXXX"
response = llm.invoke(prompt)
Let’s now look at some prompts and responses:
Attempt 1
Prompt: How can I use SDPA with BERT in transformers?
Straightforward QA Response:
To use Sparse Distributed Memory (SDPA) with BERT in the Hugging Face Transformers library, follow these steps:
-
Install Transformers:
pip install transformers -
Load BERT Model with SDPA:
from transformers import BertModel, BertTokenizer # Load the tokenizer tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') # Load the BERT model with SDPA model = BertModel.from_pretrained('bert-base-uncased', use_sdp_attention=True)
The rest of the response is truncated.
RAG QA Response:
To use Scaled Dot Product Attention (SDPA) with BERT in the transformers library, you can follow these steps:
- Load the BERT model with SDPA: You need to specify the
attn_implementationparameter as"sdpa"when loading the BERT model. Additionally, for better performance, you can load the model in half-precision (e.g.,torch.float16). -
Example Code:
from transformers import BertModel # Load the BERT model with SDPA and in half-precision model = BertModel.from_pretrained( "bert-base-uncased", torch_dtype=torch.float16, attn_implementation="sdpa" )
This setup ensures that the BERT model uses Scaled Dot Product Attention and operates in half-precision for improved speed during training and inference.
Observation: The RAG system produces the correct code snippet while the simple QA hallucinates and produces incorrect code.
Attempt 2
Prompt: What are the possible options for position_embedding_type for BERT in transformers?
Straightforward QA Response:
The possible options for position_embedding_type for BERT in the Hugging Face Transformers library are:
absoluterelative_keyrelative_key_query
These options determine the type of positional embeddings used in the BERT model.
RAG QA Response:
The possible options for position_embedding_type for BERT in transformers are:
- “absolute”
- “relative_key”
- “relative_key_query”
Observation: Both the systems produce the right response as GPT-4o training data might contain this documentation.
Attempt 3
Prompt: How can I perform next sentence prediction using BERT in transformers?
Straightforward QA Response:
To perform next sentence prediction using BERT in the Hugging Face Transformers library, follow these steps:
-
Install the Transformers library:
pip install transformers -
Load the BERT model and tokenizer:
from transformers import BertTokenizer, BertForNextSentencePrediction import torch tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertForNextSentencePrediction.from_pretrained('bert-base-uncased') -
Prepare the input sentences:
sentence_a = "The quick brown fox jumps over the lazy dog." sentence_b = "The dog did not seem to mind." encoding = tokenizer(sentence_a, sentence_b, return_tensors='pt') -
Perform the next sentence prediction:
outputs = model(**encoding) logits = outputs.logits -
Interpret the results:
softmax = torch.nn.Softmax(dim=1) probs = softmax(logits) is_next_sentence_prob = probs[0][0].item() is_not_next_sentence_prob = probs[0][1].item() print(f"Is next sentence: {is_next_sentence_prob:.4f}") print(f"Is not next sentence: {is_not_next_sentence_prob:.4f}")
This will give you the probabilities of whether sentence_b is the next sentence following sentence_a.
RAG QA Response:
Here is a code example based on the provided context:
from transformers import BertTokenizer, FlaxBertForSequenceClassification
# Load the tokenizer and model
tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
model = FlaxBertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
# Define the sentences
prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
next_sentence = "The sky is blue due to the shorter wavelength of blue light."
# Tokenize and encode the sentences
encoding = tokenizer(prompt, next_sentence, return_tensors="jax")
# Perform the prediction
outputs = model(**encoding)
logits = outputs.logits
# Interpret the logits
if logits[0, 0] < logits[0, 1]:
print("The next sentence is random.")
else:
print("The next sentence is consecutive.")
In this example:
- The
BertTokenizerandFlaxBertForSequenceClassificationare used to load the tokenizer and model. - The
promptandnext_sentenceare tokenized and encoded together. - The encoded inputs are passed to the model to get the logits.
- The logits are compared to determine if the sentences are consecutive or not.
Make sure to adjust the return_tensors parameter based on the framework you are using ("jax" for JAX/Flax, "pt" for PyTorch).
Observation: The simple QA system gives the correct response but the RAG QA system fails to do so. This is because the system gets the wrong context texts.
Conclusion
Combining Retrieval-Augmented Generation (RAG) with Large Language Models (LLMs) can significantly enhance your data retrieval and processing capabilities. However, to get the best performance, we need to carefully choose the chunk size, retrieval methods, and value of K for retrieval. Following the step-by-step guide you can start building your own RAG applications. Happy coding!